
DP-201 Exam Questions - Online Test
DP-201 Premium VCE File

150 Lectures, 20 Hours

Certleader offers free demo for DP-201 exam. "Designing an Azure Data Solution", also known as DP-201 exam, is a Microsoft Certification. This set of posts, Passing the Microsoft DP-201 exam, will help you answer those questions. The DP-201 Questions & Answers covers all the knowledge points of the real exam. 100% real Microsoft DP-201 exams and revised by experts!
Check DP-201 free dumps before getting the full version:
NEW QUESTION 1
You have a Windows-based solution that analyzes scientific data. You are designing a cloud-based solution that performs real-time analysis of the data.
You need to design the logical flow for the solution.
Which two actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Send data from the application to an Azure Stream Analytics job.
- B. Use an Azure Stream Analytics job on an edge devic
- C. Ingress data from an Azure Data Factory instance and build queries that output to Power BI.
- D. Use an Azure Stream Analytics job in the clou
- E. Ingress data from the Azure Event Hub instance and build queries that output to Power BI.
- F. Use an Azure Stream Analytics job in the clou
- G. Ingress data from an Azure Event Hub instance and build queries that output to Azure Data Lake Storage.
- H. Send data from the application to Azure Data Lake Storage.
- I. Send data from the application to an Azure Event Hub instance.
Answer: CF
Explanation:
Stream Analytics has first-class integration with Azure data streams as inputs from three kinds of resources: Azure Event Hubs
Azure IoT Hub Azure Blob storage References:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-define-inputs
NEW QUESTION 2
You need to design the image processing and storage solutions.
What should you recommend? To answer, select the appropriate configuration in the answer area. NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
References:
https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/batch-processing https://docs.microsoft.com/en-us/azure/sql-database/sql-database-service-tier-hyperscale
NEW QUESTION 3
You need to recommend the appropriate storage and processing solution? What should you recommend?
- A. Enable auto-shrink on the database.
- B. Flush the blob cache using Windows PowerShell.
- C. Enable Apache Spark RDD (RDD) caching.
- D. Enable Databricks IO (DBIO) caching.
- E. Configure the reading speed using Azure Data Studio.
Answer: C
Explanation:
Scenario: You must be able to use a file system view of data stored in a blob. You must build an architecture that will allow Contoso to use the DB FS filesystem layer over a blob store.
Databricks File System (DBFS) is a distributed file system installed on Azure Databricks clusters. Files in DBFS persist to Azure Blob storage, so you won’t lose data even after you terminate a cluster.
The Databricks Delta cache, previously named Databricks IO (DBIO) caching, accelerates data reads by creating copies of remote files in nodes’ local storage using a fast intermediate data format. The data is cached automatically whenever a file has to be fetched from a remote location. Successive reads of the same data are then performed locally, which results in significantly improved reading speed.
NEW QUESTION 4
You are designing an Azure SQL Data Warehouse for a financial services company. Azure Active Directory will be used to authenticate the users.
You need to ensure that the following security requirements are met:  Department managers must be able to create new database. The IT department must assign users to databases. Permissions granted must be minimized.
Department managers must be able to create new database. The IT department must assign users to databases. Permissions granted must be minimized.
Which role memberships should you recommend? To answer, drag the appropriate roles to the correct groups. Each role may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.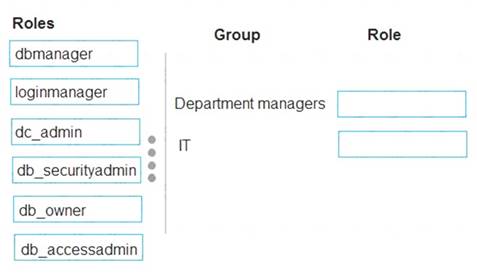
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: dbmanager
Members of the dbmanager role can create new databases. Box 2: db_accessadmin
Members of the db_accessadmin fixed database role can add or remove access to the database for Windows logins, Windows groups, and SQL Server logins.
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-manage-logins
NEW QUESTION 5
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company is developing a solution to manage inventory data for a group of automotive repair shops. The
solution will use Azure SQL Data Warehouse as the data store. Shops will upload data every 10 days.
Data corruption checks must run each time data is uploaded. If corruption is detected, the corrupted data must be removed.
You need to ensure that upload processes and data corruption checks do not impact reporting and analytics processes that use the data warehouse.
Proposed solution: Insert data from shops and perform the data corruption check in a transaction. Rollback transfer if corruption is detected.
Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
Instead, create a user-defined restore point before data is uploaded. Delete the restore point after data corruption checks complete.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/backup-and-restore
NEW QUESTION 6
You need to recommend an Azure SQL Database service tier. What should you recommend?
- A. Business Critical
- B. General Purpose
- C. Premium
- D. Standard
- E. Basic
Answer: C
Explanation:
The data engineers must set the SQL Data Warehouse compute resources to consume 300 DWUs. Note: There are three architectural models that are used in Azure SQL Database: General Purpose/Standard Business Critical/Premium Hyperscale
NEW QUESTION 7
You need to design the solution for analyzing customer data. What should you recommend?
- A. Azure Databricks
- B. Azure Data Lake Storage
- C. Azure SQL Data Warehouse
- D. Azure Cognitive Services
- E. Azure Batch
Answer: A
Explanation:
Customer data must be analyzed using managed Spark clusters. You create spark clusters through Azure Databricks. References:
https://docs.microsoft.com/en-us/azure/azure-databricks/quickstart-create-databricks-workspace-portal
NEW QUESTION 8
You need to recommend a backup strategy for CONT_SQL1 and CONT_SQL2. What should you recommend?
- A. Use AzCopy and store the data in Azure.
- B. Configure Azure SQL Database long-term retention for all databases.
- C. Configure Accelerated Database Recovery.
- D. Use DWLoader.
Answer: B
Explanation:
Scenario: The database backups have regulatory purposes and must be retained for seven years.
NEW QUESTION 9
You need to design the system for notifying law enforcement officers about speeding vehicles.
How should you design the pipeline? To answer, drag the appropriate services to the correct locations. Each service may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.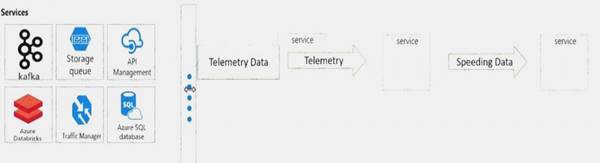
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 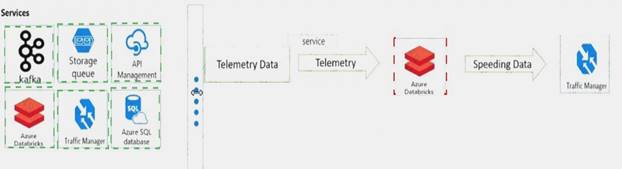
NEW QUESTION 10
A company manufactures automobile parts. The company installs IoT sensors on manufacturing machinery. You must design a solution that analyzes data from the sensors.
You need to recommend a solution that meets the following requirements: Data must be analyzed in real-time.
Data queries must be deployed using continuous integration. Data must be visualized by using charts and graphs.
Data must be available for ETL operations in the future. The solution must support high-volume data ingestion.
Which three actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Use Azure Analysis Services to query the dat
- B. Output query results to Power BI.
- C. Configure an Azure Event Hub to capture data to Azure Data Lake Storage.
- D. Develop an Azure Stream Analytics application that queries the data and outputs to Power B
- E. Use AzureData Factory to deploy the Azure Stream Analytics application.
- F. Develop an application that sends the IoT data to an Azure Event Hub.
- G. Develop an Azure Stream Analytics application that queries the data and outputs to Power B
- H. Use AzurePipelines to deploy the Azure Stream Analytics application.
- I. Develop an application that sends the IoT data to an Azure Data Lake Storage container.
Answer: BCD
NEW QUESTION 11
You have an on-premises MySQL database that is 800 GB in size.
You need to migrate a MySQL database to Azure Database for MySQL. You must minimize service interruption to live sites or applications that use the database.
What should you recommend?
- A. Azure Database Migration Service
- B. Dump and restore
- C. Import and export
- D. MySQL Workbench
Answer: A
Explanation:
You can perform MySQL migrations to Azure Database for MySQL with minimal downtime by using the newly introduced continuous sync capability for the Azure Database Migration Service (DMS). This functionality limits the amount of downtime that is incurred by the application. References:
https://docs.microsoft.com/en-us/azure/mysql/howto-migrate-online
NEW QUESTION 12
You are designing an Azure Data Factory pipeline for processing data. The pipeline will process data that is stored in general-purpose standard Azure storage.
You need to ensure that the compute environment is created on-demand and removed when the process is completed.
Which type of activity should you recommend?
- A. Databricks Python activity
- B. Data Lake Analytics U-SQL activity
- C. HDInsight Pig activity
- D. Databricks Jar activity
Answer: C
Explanation:
The HDInsight Pig activity in a Data Factory pipeline executes Pig queries on your own or on-demand HDInsight cluster.
References:
https://docs.microsoft.com/en-us/azure/data-factory/transform-data-using-hadoop-pig
NEW QUESTION 13
You are designing a data processing solution that will run as a Spark job on an HDInsight cluster. The solution will be used to provide near real-time information about online ordering for a retailer.
The solution must include a page on the company intranet that displays summary information. The summary information page must meet the following requirements: Display a summary of sales to date grouped by product categories, price range, and review scope. Display sales summary information including total sales, sales as compared to one day ago and sales as compared to one year ago. Reflect information for new orders as quickly as possible. You need to recommend a design for the solution.
Display a summary of sales to date grouped by product categories, price range, and review scope. Display sales summary information including total sales, sales as compared to one day ago and sales as compared to one year ago. Reflect information for new orders as quickly as possible. You need to recommend a design for the solution.
What should you recommend? To answer, select the appropriate configuration in the answer area.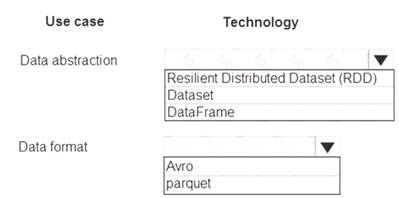
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: DataFrame
DataFrames
Best choice in most situations.
Provides query optimization through Catalyst. Whole-stage code generation.
Direct memory access.
Low garbage collection (GC) overhead.
Not as developer-friendly as DataSets, as there are no compile-time checks or domain object programming. Box 2: parquet
The best format for performance is parquet with snappy compression, which is the default in Spark 2.x. Parquet stores data in columnar format, and is highly optimized in Spark.
NEW QUESTION 14
You need to design a backup solution for the processed customer data. What should you include in the design?
- A. AzCopy
- B. AdlCopy
- C. Geo-Redundancy
- D. Geo-Replication
Answer: C
Explanation:
Scenario: All data must be backed up in case disaster recovery is required.
Geo-redundant storage (GRS) is designed to provide at least 99.99999999999999% (16 9's) durability of objects over a given year by replicating your data to a secondary region that is hundreds of miles away from
the primary region. If your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a disaster in which the primary region isn't recoverable. References:
https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy-grs
NEW QUESTION 15
You are designing an application. You plan to use Azure SQL Database to support the application.
The application will extract data from the Azure SQL Database and create text documents. The text documents will be placed into a cloud-based storage solution. The text storage solution must be accessible from an SMB network share.
You need to recommend a data storage solution for the text documents. Which Azure data storage type should you recommend?
- A. Queue
- B. Files
- C. Blob
- D. Table
Answer: B
Explanation:
Azure Files enables you to set up highly available network file shares that can be accessed by using the standard Server Message Block (SMB) protocol.
References:
https://docs.microsoft.com/en-us/azure/storage/common/storage-introduction https://docs.microsoft.com/en-us/azure/storage/tables/table-storage-overview
NEW QUESTION 16
You are designing a solution for a company. The solution will use model training for objective classification. You need to design the solution.
What should you recommend?
- A. an Azure Cognitive Services application
- B. a Spark Streaming job
- C. interactive Spark queries
- D. Power BI models
- E. a Spark application that uses Spark MLib.
Answer: E
Explanation:
Spark in SQL Server big data cluster enables AI and machine learning.
You can use Apache Spark MLlib to create a machine learning application to do simple predictive analysis on an open dataset.
MLlib is a core Spark library that provides many utilities useful for machine learning tasks, including utilities that are suitable for: Classification Regression Clustering Topic modeling Singular value decomposition (SVD) and principal component analysis (PCA) Hypothesis testing and calculating sample statistics
References:
https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-machine-learning-mllib-ipython
NEW QUESTION 17
You need to design the image processing solution to meet the optimization requirements for image tag data. What should you configure? To answer, drag the appropriate setting to the correct drop targets.
Each source may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Tagging data must be uploaded to the cloud from the New York office location.
Tagging data must be replicated to regions that are geographically close to company office locations.
NEW QUESTION 18
A company is developing a mission-critical line of business app that uses Azure SQL Database Managed Instance. You must design a disaster recovery strategy for the solution.
You need to ensure that the database automatically recovers when full or partial loss of the Azure SQL Database service occurs in the primary region.
What should you recommend?
- A. Failover-group
- B. Azure SQL Data Sync
- C. SQL Replication
- D. Active geo-replication
Answer: A
Explanation:
Auto-failover groups is a SQL Database feature that allows you to manage replication and failover of a group of databases on a SQL Database server or all databases in a Managed Instance to another region (currently in public preview for Managed Instance). It uses the same underlying technology as active geo-replication. You can initiate failover manually or you can delegate it to the SQL Database service based on a user-defined policy.
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-auto-failover-group
NEW QUESTION 19
A company stores large datasets in Azure, including sales transactions and customer account information. You must design a solution to analyze the data. You plan to create the following HDInsight clusters:
You need to ensure that the clusters support the query requirements.
Which cluster types should you recommend? To answer, select the appropriate configuration in the answer area.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Interactive Query
Choose Interactive Query cluster type to optimize for ad hoc, interactive queries. Box 2: Hadoop
Choose Apache Hadoop cluster type to optimize for Hive queries used as a batch process.
Note: In Azure HDInsight, there are several cluster types and technologies that can run Apache Hive queries. When you create your HDInsight cluster, choose the appropriate cluster type to help optimize performance for your workload needs.
For example, choose Interactive Query cluster type to optimize for ad hoc, interactive queries. Choose Apache Hadoop cluster type to optimize for Hive queries used as a batch process. Spark and HBase cluster types can also run Hive queries.
References:
https://docs.microsoft.com/bs-latn-ba/azure/hdinsight/hdinsight-hadoop-optimize-hive-query?toc=%2Fko-kr%2
NEW QUESTION 20
You are designing an Azure Databricks cluster that runs user-defined local processes. You need to recommend a cluster configuration that meets the following requirements:
• Minimize query latency.
• Reduce overall costs.
• Maximize the number of users that can run queries on the cluster at the same time. Which cluster type should you recommend?
- A. Standard with Autoscaling
- B. High Concurrency with Auto Termination
- C. High Concurrency with Autoscaling
- D. Standard with Auto Termination
Answer: C
Explanation:
High Concurrency clusters allow multiple users to run queries on the cluster at the same time, while minimizing query latency. Autoscaling clusters can reduce overall costs compared to a statically-sized cluster.
References:
https://docs.azuredatabricks.net/user-guide/clusters/create.html https://docs.azuredatabricks.net/user-guide/clusters/high-concurrency.html#high-concurrency https://docs.azuredatabricks.net/user-guide/clusters/terminate.html https://docs.azuredatabricks.net/user-guide/clusters/sizing.html#enable-and-configure-autoscaling
NEW QUESTION 21
You need to recommend a solution for storing customer data. What should you recommend?
- A. Azure SQL Data Warehouse
- B. Azure Stream Analytics
- C. Azure Databricks
- D. Azure SQL Database
Answer: C
Explanation:
From the scenario:
Customer data must be analyzed using managed Spark clusters.
All cloud data must be encrypted at rest and in transit. The solution must support: parallel processing of customer data.
References:
https://www.microsoft.com/developerblog/2021/01/18/running-parallel-apache-spark-notebook-workloads-on-a
NEW QUESTION 22
You are designing a recovery strategy for your Azure SQL Databases.
The recovery strategy must use default automated backup settings. The solution must include a Point-in time restore recovery strategy.
You need to recommend which backups to use and the order in which to restore backups.
What should you recommend? To answer, select the appropriate configuration in the answer area.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
All Basic, Standard, and Premium databases are protected by automatic backups. Full backups are taken every week, differential backups every day, and log backups every 5 minutes.
References:
https://azure.microsoft.com/sv-se/blog/azure-sql-database-point-in-time-restore/
NEW QUESTION 23
You plan to use Azure SQL Database to support a line of business app.
You need to identify sensitive data that is stored in the database and monitor access to the data. Which three actions should you recommend? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A. Enable Data Discovery and Classification.
- B. Implement Transparent Data Encryption (TDE).
- C. Enable Auditing.
- D. Run Vulnerability Assessment.
- E. Use Advanced Threat Protection.
Answer: CDE
NEW QUESTION 24
You are designing a data processing solution that will implement the lambda architecture pattern. The solution will use Spark running on HDInsight for data processing.
You need to recommend a data storage technology for the solution.
Which two technologies should you recommend? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
- A. Azure Cosmos DB
- B. Azure Service Bus
- C. Azure Storage Queue
- D. Apache Cassandra
- E. Kafka HDInsight
Answer: AE
Explanation:
To implement a lambda architecture on Azure, you can combine the following technologies to accelerate realtime big data analytics:
Azure Cosmos DB, the industry's first globally distributed, multi-model database service.
Apache Spark for Azure HDInsight, a processing framework that runs large-scale data analytics applications
Azure Cosmos DB change feed, which streams new data to the batch layer for HDInsight to process The Spark to Azure Cosmos DB Connector
E: You can use Apache Spark to stream data into or out of Apache Kafka on HDInsight using DStreams. References:
https://docs.microsoft.com/en-us/azure/cosmos-db/lambda-architecture
NEW QUESTION 25
......
Recommend!! Get the Full DP-201 dumps in VCE and PDF From Dumpscollection, Welcome to Download: http://www.dumpscollection.net/dumps/DP-201/ (New 74 Q&As Version)
- [2021-New] Microsoft 70-413 Dumps With Update Exam Questions (101-108)
- [2021-New] Microsoft 70-412 Dumps With Update Exam Questions (21-30)
- [2021-New] Microsoft 98-367 Dumps With Update Exam Questions (1-10)
- [2021-New] Microsoft 98-367 Dumps With Update Exam Questions (31-40)
- [2021-New] Microsoft 70-981 Dumps With Update Exam Questions (81-90)
- [2021-New] Microsoft 70-331 Dumps With Update Exam Questions (51-60)
- [2021-New] Microsoft 70-469 Dumps With Update Exam Questions (101-110)
- [2021-New] Microsoft 70-346 Dumps With Update Exam Questions (21-30)
- [2021-New] Microsoft 70-413 Dumps With Update Exam Questions (51-60)
- [2021-New] Microsoft 70-385 Dumps With Update Exam Questions (1-10)