
Professional-Machine-Learning-Engineer Exam Questions - Online Test
Professional-Machine-Learning-Engineer Premium VCE File

150 Lectures, 20 Hours

Cause all that matters here is passing the Google Professional-Machine-Learning-Engineer exam. Cause all that you need is a high score of Professional-Machine-Learning-Engineer Google Professional Machine Learning Engineer exam. The only one thing you need to do is downloading Exambible Professional-Machine-Learning-Engineer exam study guides now. We will not let you down with our money-back guarantee.
Online Google Professional-Machine-Learning-Engineer free dumps demo Below:
NEW QUESTION 1
You have trained a text classification model in TensorFlow using Al Platform. You want to use the trained model for batch predictions on text data stored in BigQuery while minimizing computational overhead. What should you do?
- A. Export the model to BigQuery ML.
- B. Deploy and version the model on Al Platform.
- C. Use Dataflow with the SavedModel to read the data from BigQuery
- D. Submit a batch prediction job on Al Platform that points to the model location in Cloud Storage.
Answer: A
NEW QUESTION 2
You manage a team of data scientists who use a cloud-based backend system to submit training jobs. This system has become very difficult to administer, and you want to use a managed service instead. The data scientists you work with use many different frameworks, including Keras, PyTorch, theano. Scikit-team, and custom libraries. What should you do?
- A. Use the Al Platform custom containers feature to receive training jobs using any framework
- B. Configure Kubeflow to run on Google Kubernetes Engine and receive training jobs through TFJob
- C. Create a library of VM images on Compute Engine; and publish these images on a centralized repository
- D. Set up Slurm workload manager to receive jobs that can be scheduled to run on your cloud infrastructure.
Answer: D
NEW QUESTION 3
You want to rebuild your ML pipeline for structured data on Google Cloud. You are using PySpark to conduct data transformations at scale, but your pipelines are taking over 12 hours to run. To speed up development and pipeline run time, you want to use a serverless tool and SQL syntax. You have already moved your raw data into Cloud Storage. How should you build the pipeline on Google Cloud while meeting the speed and processing requirements?
- A. Use Data Fusion's GUI to build the transformation pipelines, and then write the data into BigQuery
- B. Convert your PySpark into SparkSQL queries to transform the data and then run your pipeline on Dataproc to write the data into BigQuery.
- C. Ingest your data into Cloud SQL convert your PySpark commands into SQL queries to transform the data, and then use federated queries from BigQuery for machine learning
- D. Ingest your data into BigQuery using BigQuery Load, convert your PySpark commands into BigQuery SQL queries to transform the data, and then write the transformations to a new table
Answer: B
NEW QUESTION 4
You have a functioning end-to-end ML pipeline that involves tuning the hyperparameters of your ML model using Al Platform, and then using the best-tuned parameters for training. Hypertuning is taking longer than expected and is delaying the downstream processes. You want to speed up the tuning job without significantly compromising its effectiveness. Which actions should you take?
Choose 2 answers
- A. Decrease the number of parallel trials
- B. Decrease the range of floating-point values
- C. Set the early stopping parameter to TRUE
- D. Change the search algorithm from Bayesian search to random search.
- E. Decrease the maximum number of trials during subsequent training phases.
Answer: DE
NEW QUESTION 5
You are an ML engineer at a bank that has a mobile application. Management has asked you to build an ML-based biometric authentication for the app that verifies a customer's identity based on their fingerprint. Fingerprints are considered highly sensitive personal information and cannot be downloaded and stored into the bank databases. Which learning strategy should you recommend to train and deploy this ML model?
- A. Differential privacy
- B. Federated learning
- C. MD5 to encrypt data
- D. Data Loss Prevention API
Answer: B
NEW QUESTION 6
You work for an online retail company that is creating a visual search engine. You have set up an end-to-end ML pipeline on Google Cloud to classify whether an image contains your company's product. Expecting the release of new products in the near future, you configured a retraining functionality in the pipeline so that new data can be fed into your ML models. You also want to use Al Platform's continuous evaluation service to ensure that the models have high accuracy on your test data set. What should you do?
- A. Keep the original test dataset unchanged even if newer products are incorporated into retraining
- B. Extend your test dataset with images of the newer products when they are introduced to retraining
- C. Replace your test dataset with images of the newer products when they are introduced to retraining.
- D. Update your test dataset with images of the newer products when your evaluation metrics drop below a pre-decided threshold.
Answer: C
NEW QUESTION 7
You developed an ML model with Al Platform, and you want to move it to production. You serve a few thousand queries per second and are experiencing latency issues. Incoming requests are served by a load balancer that distributes them across multiple Kubeflow CPU-only pods running on Google Kubernetes Engine (GKE). Your goal is to improve the serving latency without changing the underlying infrastructure. What should you do?
- A. Significantly increase the max_batch_size TensorFlow Serving parameter
- B. Switch to the tensorflow-model-server-universal version of TensorFlow Serving
- C. Significantly increase the max_enqueued_batches TensorFlow Serving parameter
- D. Recompile TensorFlow Serving using the source to support CPU-specific optimizations Instruct GKE to choose an appropriate baseline minimum CPU platform for serving nodes
Answer: A
NEW QUESTION 8
You work on a growing team of more than 50 data scientists who all use Al Platform. You are designing a strategy to organize your jobs, models, and versions in a clean and scalable way. Which strategy should you choose?
- A. Set up restrictive I AM permissions on the Al Platform notebooks so that only a single user or group can access a given instance.
- B. Separate each data scientist's work into a different project to ensure that the jobs, models, and versions created by each data scientist are accessible only to that user.
- C. Use labels to organize resources into descriptive categorie
- D. Apply a label to each created resource so that users can filter the results by label when viewing or monitoring the resources
- E. Set up a BigQuery sink for Cloud Logging logs that is appropriately filtered to capture information about Al Platform resource usage In BigQuery create a SQL view that maps users to the resources they are using.
Answer: B
NEW QUESTION 9
You have trained a deep neural network model on Google Cloud. The model has low loss on the training data, but is performing worse on the validation data. You want the model to be resilient to overfitting. Which strategy should you use when retraining the model?
- A. Apply a dropout parameter of 0 2, and decrease the learning rate by a factor of 10
- B. Apply a 12 regularization parameter of 0.4, and decrease the learning rate by a factor of 10.
- C. Run a hyperparameter tuning job on Al Platform to optimize for the L2 regularization and dropout parameters
- D. Run a hyperparameter tuning job on Al Platform to optimize for the learning rate, and increase the number of neurons by a factor of 2.
Answer: A
NEW QUESTION 10
You work for a toy manufacturer that has been experiencing a large increase in demand. You need to build an ML model to reduce the amount of time spent by quality control inspectors checking for product defects. Faster defect detection is a priority. The factory does not have reliable Wi-Fi. Your company wants to implement the new ML model as soon as possible. Which model should you use?
- A. AutoML Vision model
- B. AutoML Vision Edge mobile-versatile-1 model
- C. AutoML Vision Edge mobile-low-latency-1 model
- D. AutoML Vision Edge mobile-high-accuracy-1 model
Answer: A
NEW QUESTION 11
Your organization's call center has asked you to develop a model that analyzes customer sentiments in each call. The call center receives over one million calls daily, and data is stored in Cloud Storage. The data collected must not leave the region in which the call originated, and no Personally Identifiable Information (Pll) can be stored or analyzed. The data science team has a third-party tool for visualization and access which requires a SQL ANSI-2011 compliant interface. You need to select components for data processing and for analytics. How should the data pipeline be designed?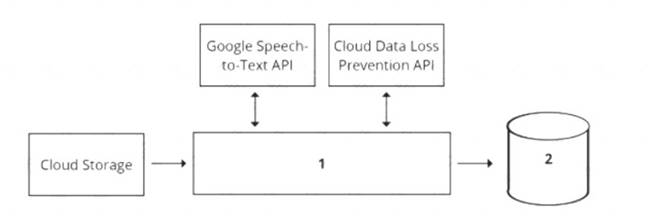
- A. 1 = Dataflow, 2 = BigQuery
- B. 1 = Pub/Sub, 2 = Datastore
- C. 1 = Dataflow, 2 = Cloud SQL
- D. 1 = Cloud Function, 2 = Cloud SQL
Answer: D
NEW QUESTION 12
You are building a linear regression model on BigQuery ML to predict a customer's likelihood of purchasing your company's products. Your model uses a city name variable as a key predictive component. In order to train and serve the model, your data must be organized in columns. You want to prepare your data using the least amount of coding while maintaining the predictable variables. What should you do?
- A. Create a new view with BigQuery that does not include a column with city information
- B. Use Dataprep to transform the state column using a one-hot encoding method, and make each city a column with binary values.
- C. Use Cloud Data Fusion to assign each city to a region labeled as 1, 2, 3, 4, or 5r and then use that number to represent the city in the model.
- D. Use TensorFlow to create a categorical variable with a vocabulary list Create the vocabulary file, and upload it as part of your model to BigQuery ML.
Answer: C
NEW QUESTION 13
You need to build classification workflows over several structured datasets currently stored in BigQuery.
Because you will be performing the classification several times, you want to complete the following steps without writing code: exploratory data analysis, feature selection, model building, training, and hyperparameter tuning and serving. What should you do?
- A. Configure AutoML Tables to perform the classification task
- B. Run a BigQuery ML task to perform logistic regression for the classification
- C. Use Al Platform Notebooks to run the classification model with pandas library
- D. Use Al Platform to run the classification model job configured for hyperparameter tuning
Answer: C
NEW QUESTION 14
You need to train a computer vision model that predicts the type of government ID present in a given image using a GPU-powered virtual machine on Compute Engine. You use the following parameters:
• Optimizer: SGD
• Image shape = 224x224
• Batch size = 64
• Epochs = 10
• Verbose = 2
During training you encounter the following error: ResourceExhaustedError: out of Memory (oom) when allocating tensor. What should you do?
- A. Change the optimizer
- B. Reduce the batch size
- C. Change the learning rate
- D. Reduce the image shape
Answer: A
NEW QUESTION 15
During batch training of a neural network, you notice that there is an oscillation in the loss. How should you adjust your model to ensure that it converges?
- A. Increase the size of the training batch
- B. Decrease the size of the training batch
- C. Increase the learning rate hyperparameter
- D. Decrease the learning rate hyperparameter
Answer: C
NEW QUESTION 16
You are an ML engineer at a large grocery retailer with stores in multiple regions. You have been asked to create an inventory prediction model. Your models features include region, location, historical demand, and seasonal popularity. You want the algorithm to learn from new inventory data on a daily basis. Which algorithms should you use to build the model?
- A. Classification
- B. Reinforcement Learning
- C. Recurrent Neural Networks (RNN)
- D. Convolutional Neural Networks (CNN)
Answer: B
NEW QUESTION 17
You recently designed and built a custom neural network that uses critical dependencies specific to your organization's framework. You need to train the model using a managed training service on Google Cloud. However, the ML framework and related dependencies are not supported by Al Platform Training. Also, both your model and your data are too large to fit in memory on a single machine. Your ML framework of choice uses the scheduler, workers, and servers distribution structure. What should you do?
- A. Use a built-in model available on Al Platform Training
- B. Build your custom container to run jobs on Al Platform Training
- C. Build your custom containers to run distributed training jobs on Al Platform Training
- D. Reconfigure your code to a ML framework with dependencies that are supported by Al Platform Training
Answer: C
NEW QUESTION 18
......
Thanks for reading the newest Professional-Machine-Learning-Engineer exam dumps! We recommend you to try the PREMIUM Dumps-files.com Professional-Machine-Learning-Engineer dumps in VCE and PDF here: https://www.dumps-files.com/files/Professional-Machine-Learning-Engineer/ (138 Q&As Dumps)
- The Most Up-to-date Guide To Professional-Cloud-Architect Pdf Exam
- Verified Google Cloud-Digital-Leader Vce Online
- The Secret Of Google Professional-Data-Engineer Study Guides
- Improve Professional-Data-Engineer Practice For Google Professional Data Engineer Exam Certification
- Top Tips Of Abreast Of The Times Professional-Cloud-Architect Free Download
- All About Accurate Professional-Cloud-DevOps-Engineer Testing Bible
- The Latest Guide To Professional-Data-Engineer Simulations
- Breathing Google Associate-Cloud-Engineer Practice Online
- Accurate Google Professional-Machine-Learning-Engineer Free Exam Online
- Refined Google Associate-Cloud-Engineer Testing Engine Online